Backup Guide - how to secure crucial data
This guide tries to share thoughts about various backup strategies, risks, storage mediums, and other things to consider. I won't go into technical details or suggest any tools since every backup strategy must be created individually, and there is a wide range of requirements. I rather want to give you some kind of checklist with things to think about. There is not a perfect strategy solution or template that fits all needs.
I've tried to keep this guide accessible for personal and corporate backups.
WHY DO YOU NEED BACKUPS
The main goal of backups is data loss prevention. There are numerous risks that could cause data loss, and we try to prevent them with a backup strategy that fits our needs. I'll go into more detail in the next section.
Risks #
The following risks exist for data in production and for your backups! - There are many more, but this section will give you a feeling of the most common risks.
- Environment threats:
- flooding/water/humidity
- fire/high temperature
- earthquake/shock
- EMP/Electricity
- Human errors:
- loss of a device
- misconfiguration
- unintentional
sudo rm -rf / --no-preserve-root - lost access (password,key,...)
- Threat actors:
- ransomware
- rogue employees
- hardware theft
- data tampering
- Hardware/software:
- hardware failure
- bugs
- bitrot
Some 'disasters' affect only a single hard drive, some devices, or the whole network. A decent backup strategy mitigates those risks and helps to recover as fast as possible.
Side note: Backups do not prevent those risks, but minimize the damage and help to recover from them.
RAID/snapshots are no backups! #
RAID - redundant array of independent disks - is a method to either increase the performance, the availability and resiliency, or both. Misconfigured, it can even cause more damage; for example, a RAID0 can make the whole array useless after a disk failure. Don't let me get started with broken hardware RAID controllers or RAID expansions.
It protects against one of the most common data loss reasons: disk failure. It does not help you in case of human errors, ransomware, file corruption, and other use cases in which a backup would normally help you. And yeah, data recovery, in general, is not a function of RAID.
A RAID is not a backup.
Snapshots are short-term roll-back solutions in case of an update failure, system misconfiguration, and other critical measures. They are not independent of the VM environment, and they are often stored on the same disk as the server and still are a single point of failure. Since most snapshot solutions are not application-aware, data corruption of databases or other applications can occur when they are in progress while the snapshot was created.
Snapshots, therefore, should not be considered a valid backup!
Both solutions can be part of your backup strategy but can't replace a regular backup.
Determine what to backup and why
What and why you backup specific files highly depend on your needs. It is helpful to have an inventory of critical infrastructure to determine what to backup.
Furthermore, it is helpful to categorize data. System data (e.x. operating system), application data (e.x. configuration files), and operational data (e.x. data sheets, databases, emails). Operational data is the most important since it is necessary for daily business. This step recommends checking the size and kind of data to plan for the backup storage requirements.
Side note: I am not too familiar with certain laws or compliances like HIPAA, SOC2, PCI DSS, and so on, but talking with legal might be a good idea.
It is essential to know some processes and communicate with different departments. What is business critical, and what could wait in case of a disaster? And nobody needs a working frontend when the databases are not up and running. Knowing the processes will help you to avoid problems in the recovery phase. That said, those problems should be apparent when you test your recovery procedure.
Some other category is the frequency with which the data gets updated. An example would be: frequent (e.x. databases), rare (e.x. static content like intranet or docs), and already archived data (important, but don't have to be recovered immediately).
Remember to provide some kind of backup solution for devices like laptops and smartphones.
Data Retention Policy
With the Data Retention Policy, we try to specify how long to retain certain data. There are various factors you should consider: usefulness, compliance, laws, and so on.
Some system data, like old configuration files, can be deleted after a short time, but operational data, like invoices or contracts, must be stored for five and more years.
Side note: as mentioned before, this highly depends on your setup, and speaking to the relevant departments is recommended.
Backup/data deletion #
Deleting data or backups seems not worth talking about, but data can be easily recovered if it is not done correctly.
The methods differ from medium to medium. The most secure way would be to destroy the medium properly. Re-writing the medium with random ones and zeros multiple times and/or doing full encryption and destroying the key would be options if you want to resell the medium. Other than that, special tools can be used that differ from medium to medium.
Some laws/compliances require you to destroy data in a certain way. To make sure, speak with legal or a specific contact person.
To be secure, store your backups encrypted in the first place.
Decide the backup frequency
The frequency of your backups will determine the impact of a disaster in terms of data loss. The more frequently you do backups; the less is data loss in case a disaster occurs. There are two metrics you could consider: RTO and RPO.
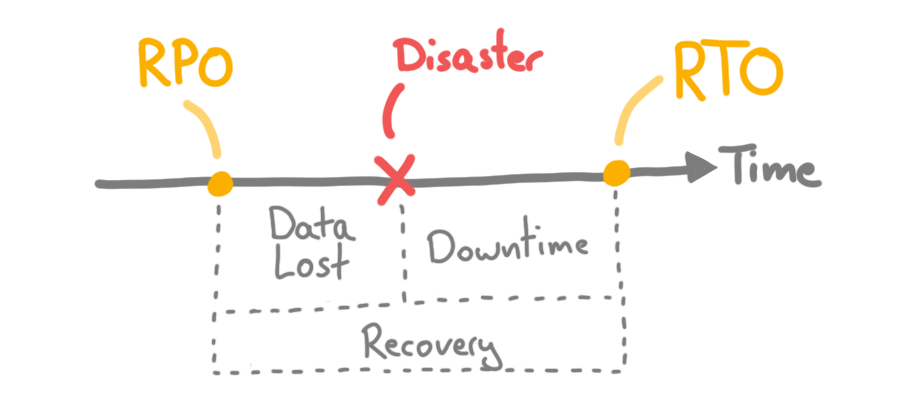
RPO (Recovery Point Objective) #
With the RPO we want to determine how much data loss can be tolerated in case of a disaster. A RPO of 12 hours requires you to do two backups a day to fulfill this requirement. It wouldn't be sufficient to have daily backups the the RPO was 3 hours.
Every system can have its own RPO.
RTO (Recovery Time Objective) #
With the RTO we want to determine the maximum tolerable amount of down time after any disaster. A RTO of 3 hours says that the system needs to be productive within 3 hours after a disaster. Some metrics to consider: cost per hour in case of a down time and external requirements like laws or contracts.
Like the RPO, every system can have its own RTO, and the RTO ends when data is recovered and it is up again.
Document everything
As in so many areas; documentation is king.
- what and why do you backup
- the frequency of backups
- the backup process
- the access to the backups
- the recovery process
It will be hectic and stressful if the DRP or backup plan is needed, so the better the documentation is, the faster you can recover your systems.
Something that should not be overlooked is a contact list. What people must be contacted to recover data and how can we reach them? Where is the offsite backup stored, and e.x. how can we reach the bank? This will save a lot of time.
Don't forget to store the documents securely, but accessible. Detached from the backup, like printed out, or on a USB stick in a safe.
How to backup!
As mentioned before, there is no perfect solution, and you must find a backup strategy that works for you. Like everything, it has pros and cons, and you have to decide what works for you. I'll show you some points to consider.
3-2-1 rule #
- I want to start with the well-known 3-2-1 rule:
- have 3 copies of your data
- have 2 different storage methods/mediums
- have 1 copy offsite
The 3-2-1 rules should be considered the bare minimum of every backup strategy. I'll go into more detail in the following points.
Have multiple copies of your data #
Who would have known? But just to be sure, consider some points.
Sounds obvious, but avoid storing backups of a system on the same system or storage.
Spread copies over multiple mediums and use different methods. Every storage medium/method has its risks, and having copies on multiple mediums increases the resiliency overall.
Locations #
Make use of different locations.
Some examples would be: - store a full backup in a bank vault or a different trusted location - store backups from data center A in data center B, and vice versa - store a backup in the cloud
Just make sure that you can access the offsite backups whenever you can and add this factor into your strategy.
Encrypt backup storage and transfer #
This is especially important for offsite backups but can be necessary for local backups too. Make sure that you use a secure encryption method, use a secure password/password or another method, and encrypt the transit and storage! Still will protect the integrity of your data from tampering of a third party, and makes your data worthless in case a third party gets access to the backups.
Important: Do not lose the keys! - Backup your decryption method, store it securely (not with your backups), and ensure that the decryption key is accessible in any disaster scenario!
Think about the right tools #
Could you access your backups in 10 years? Is the technology still around? Is the de-/encrpytion service provider still in business?
It is recommended to use well-known open-source services. Niche and proprietary services can be attractive short term, but they add a layer of dependency.
Side note: store an unencrypted version of the encryption tool with your backups, so it will be available if it is needed.
Try to automate as much as possible, so backups won't be forgotten, and make sure that the backup process doesn't disrupt the daily business.
Store backups immutable/read-only #
Keeping the backup storage immutable prevents anyone from tampering with the backups and increases the data integrity. There are cases in which you have to delete certain data from backups, but in general, it is recommended to store them immutable.
Choose the right storage medium #
There are multiple factors that will play into the choice of a storage medium.
- How much data do you have to store?
- How long do you need to store it?
- How much money do you want to spend?
- and many more
One example could be M-Discs: they claim to have a lifetime of 1000 years and have a capacity between 25 and 100 GB. It can be an option for personal backups or small but critical company backups, but a 10 TB backup of operational data? - That is not a practical solution.
Things to consider:
- lifetime/sustainably
- accessibility
- future proof technology
- setup costs
- operational cost over time/per GB/TB
- practically
- write/read speed
- ...
The choice of medium will affect the recovery process and speed and is overall important.
Have the recovery process in mind #
Think backward from a recovery standpoint. You have to recover system 'A' and what else must be up to get system 'A' running again? This might give you another perspective.
Avoid single point of failures #
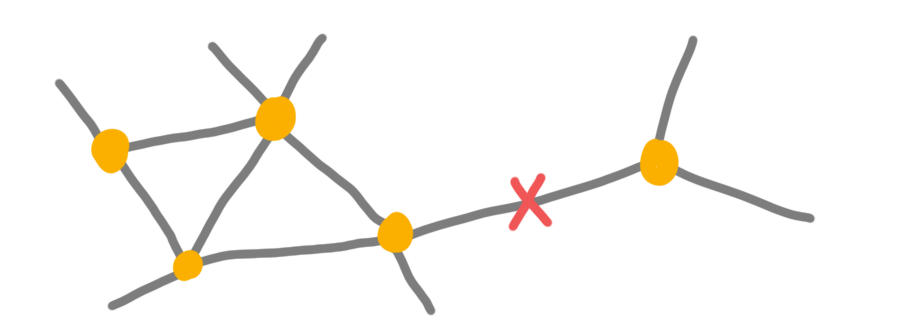
There are plenty of examples: single backup server, a single person with access to backups, single internet connection with cloud backups only, and so on.
Use different backup types #
I won't go into detail, but the main goal is to save time and storage.
Full backups - as the name implies - is a backup of all data.

Differential backups store the changes from the last full backup.

Incremental backups store the changes from the last full backup or incremental backup.
Restrict and secure access to the backups #
Backups should only be accessible by trusted parties. Admins only, separate network, MFA, and other security measurements are recommended. The goal is further to limit the risks of tampering, theft or deletion.
Side note: make sure that you do not lock yourself out. This is critical and should be tested regularly.
Trust but verify
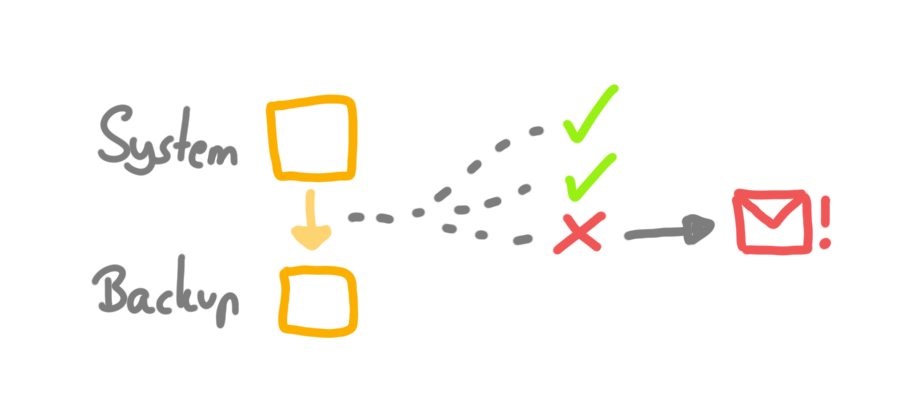
Monitor your backup process and backup storage. Check the logs regularly and implement some kind of alerting/notification system.
Things to look for: failed backup jobs, unusual activities, access attempts, and so.
Side note: More details follow in the recovery section, but make sure to monitor and test the health of the backup medium too.
Let third party/experts audit your backup strategy. It is easy to overlook certain things, and it can be beneficial to have another perspective.
Test recoverability regularly

Test your back regularly. From A to B, and play through various scenarios.
- do you still have access to everything?
- can you encrypt the backup?
- can you recover the needed system/data?
- Did a process change?
- is the documentation/manual still up to date?
- are we still in our required recovery time?
- is the contact list still up-to-date?
Something you should do too:
- update contact list
- manual/documentation
- include new coworkers to show them the process
- check health of hardware (storage, etc)
It is recommended to test it with different hardware/software to increase the resilience. If this is not an option, keep backup hardware and spare parts around.
Re-evaluate the backup strategy regularly #
Systems, processes, people, requirements, and almost anything else change over time. This requires re-evaluating the backup strategy regularly. Notes from the test recoveries and conversations with contact persons should help to adjust the strategy accordingly.
Conclusion
Creating a good backup strategy can be challenging, but it is crucial in the end.
This is the first version of this guide and I try to get into more detail in the future.